By offloading work that requires high-speed parallel processing to the FPGA and leaving the processor to work with high-speed serial processing, the system's cost-effectiveness can be optimized while reducing system requirements. Sub-system partition selection scheme FPGAs can be used with DSP processors as stand-alone preprocessor (sometimes post-processor) devices or as coprocessors. In the pre-processing architecture, the FPGA is directly in the data path responsible for signal preprocessing. The pre-processed signal can be efficiently and economically handed over to the DSP processor for low-speed subsequent processing. In the co-processing architecture, the FPGA is placed side-by-side with the DSP, which offloads specific algorithm functions to the FPGA in order to achieve higher processing speeds than can be achieved with the DSP processor alone. The processing results of the FPGA are sent back to the DSP or sent to other devices for further processing, transmission, or storage (Figure 1). The choice of pre-processing, post-processing, or co-processing often depends on the timing margin required to move data between the processor and the FPGA and its effect on overall latency. Although the co-processing solution is the topology most often considered by designers (mainly because the DSP can control the data transfer process more directly), this is not always the best overall strategy. For example, the latest 3G LTE specification shortens the transmission time interval (TTI) from 2ms for HSDPA and 10ms for WCDMA to 1ms. This essentially requires that the data processing time between the receiver and the output of the MAC layer is shorter than 1,000 ?sec. As shown in Figure 2, using the SRIO port on a DSP running at 3.125 Gbps (using 8b/10b encoding, the Turbo decoding function requires a 200-bit overhead) causes a 230-sec. DSP-to-FPGA transmission delay (that is, Nearly a quarter of the TTI period is used only for data transmission. Combined with other predictable delays, to meet these system timings, when the user is 50, the required turbo codec performance is as high as 75.8 Mbps. Using an FPGA to treat the Turbo codec as a substantially independent postprocessor not only eliminates DSP latency but also saves time because it does not require high bandwidth to transfer data between the DSP and the FPGA. This reduces the Turbo decoder's throughput to 47 Mbps, allowing more economical devices to be selected and reducing system power consumption. Another consideration is whether to use soft-embedded or hard-embedded processor IP on the Xilinx FPGA to offload certain system processing tasks, which may further reduce cost, power consumption, and space. With such a large amount of signal processing resources, it is possible to better distribute various complex functions (such as baseband processing) among DSP processors, FPGA configurable logic blocks (CLBs), embedded FPGA DSP blocks, and FPGA embedded processors. Complex features). Xilinx offers two types of embedded processors: MicroBlaze soft-core processors (commonly used for system control) and higher-performance PowerPC hard-core embedded processors (for more complex tasks). The advantages provided by the FPGA embedded processor allow all non-critical operations to be incorporated into software running on the embedded processor, thereby minimizing the total amount of hardware resources required by the overall system. The importance of software and IP The key issue is how to unlock this potential capability. You must consider which software you need to use to abstract the complexity of the problem and which IPs you can use. You should consider using FPGAs to provide the best solution for the key parts. Xilinx is committed to developing industry-leading tools and architectures that enable efficient FPGA solutions at higher levels of abstraction than HDL tools such as MATLAB models and C code can provide. Using Xilinx's system-generated development tools and AccelDSP synthesis tools specifically for DSP, it is possible to link algorithms from algorithm to silicon as seamlessly as possible. There is an increasingly important team of tool providers, whose products are being upgraded to the Electronic System Level (ESL) through the C/C++ to logic gate design process. The purpose of the ESL design tool is to provide a complete system-level approach to generate and integrate hardware acceleration functions and the control code of the processor that controls these functions. There is no single high-level language or software tool that fits all the different units seen in today's complex systems. The choice of language and design process depends on the customer and sometimes depends on the specific engineer. Therefore, Xilinx has developed a comprehensive set of integrated functions to meet customer needs and provide the best design environment (see Figure 3). This article summary In addition, Xilinx is investing heavily in providing a broad range of high-value IP, board and reference designs to cover many key parts of RF card and baseband applications, including FFT/iFFT, modulation, digital up-down conversion and crest factor The lower circuit etc. An example of this key initiative is the development of industry-leading high-performance FEC features optimized for specific wireless standards and FPGA architectures, such as turbo encoders and decoders. As we show when analyzing 3G LTE delay and Turbo decoder traffic requirements, the hardware acceleration of the FEC function and its effect on the system architecture are increasingly imperative in modern wireless device design. Although some expert DSP processors have integrated such functions in the form of embedded modules, the development of FEC functional parameters that comply with the new wireless standard to form an embedded acceleration module in silicon chips usually takes several months. Once embedding is achieved, there will also be legacy problems. Occasionally, functions in the embedded module may not work as required. At the same time, standards have evolved rapidly, and new standards that cannot be supported by fixed embedded modules are included in the current standards from time to time. Given these situations, designers need flexibility. They want the ability to quickly develop and deploy complex baseband functions such as FEC, and then modify these functions based on feedback from field trials and the progress of standardization efforts. Maybe they want to join their own proprietary IP to show their solutions in the market. Because of this situation, designers should not only consider the solution portfolio offered by a certain provider at the moment, but should also understand whether these solutions are easy to modify and what level of support and tools the provider can provide. Big Water Tank Robot Vacuum Cleaners Big Water Tank Robot Vacuum Cleaners,Ultrasonic Cleaner Water Tank,Robot Vacuum Cleaner,Virtual Blocker NingBo CaiNiao Intelligent Technology Co., LTD , https://www.intelligentnewbot.com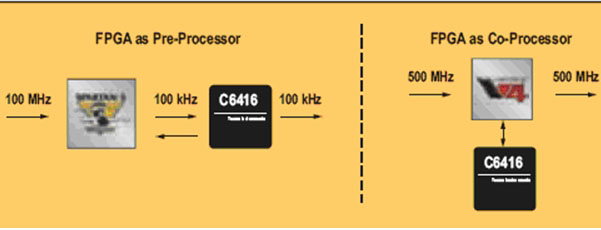
Figure 1: FPGA as a preprocessor and coprocessor solution 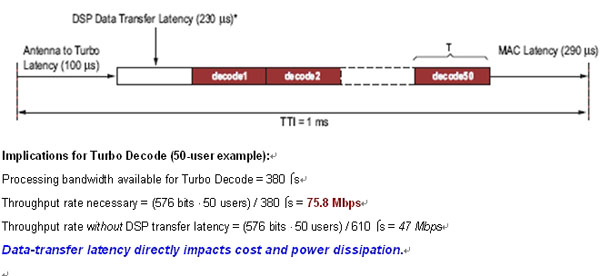
Figure 2: LTE example co-processing data transfer delay issues 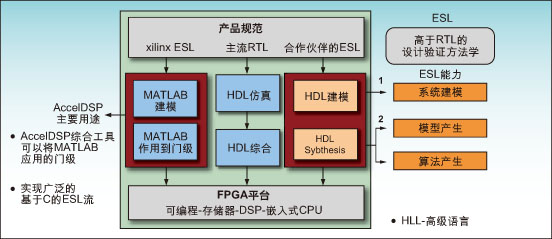
Figure 3: System Level to FPGA Design Flow
Commonly used in wireless applications such processing includes finite impulse response (FIR) filtering, fast Fourier transform (FFT), digital upconversion, and forward error correction (FEC). The Xilinx Virtex-4 and Virtex-5 architectures provide up to 512 parallel embedded DSP multipliers that operate at frequencies above 500 MHz and provide up to 256 GMAC of DSP performance.