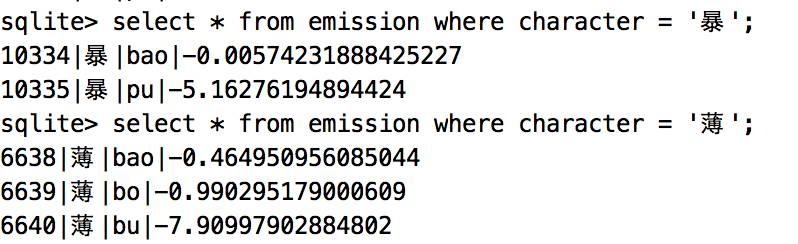
According to this training, the hidden Markov model is obtained, and a simple Pinyin input method is realized by the Viterbi algorithm. Hidden Markov Model Copy a definition of the Internet: The Hidden Markov Model is a statistical model used to describe a Markov process with implicit unknown parameters. The difficulty is to determine the implicit parameters of the process from observable parameters and then use these parameters for further analysis. The observable parameters in the Pinyin input method are pinyin, and the implicit parameters are the corresponding Chinese characters. Viterbi algorithm The Viterbi algorithm, the idea is dynamic programming, the code is relatively simple and will not be described. Code interpretation Model definition See the model/table.py file for the code. For the three probability matrices of Hidden Markov, three data table storages are designed. The advantage of this is obvious. The transfer probability matrix of Chinese characters is a very large sparse matrix. The direct file storage takes up a lot of space, and can only be read into the memory at one time when loading, not only the memory is high but also the loading speed is slow. In addition, the join operation of the database is very convenient for the probability calculation in the viterbi algorithm. The data sheet is defined as follows: classTransition(BaseModel): __tablename__ = 'transition' Id = Column(Integer,primary_key=True) Previous = Column(String(1),nullable=False) Behind = Column(String(1),nullable=False) Potential = Column(Float,nullable=False) classEmission(BaseModel): __tablename__ = 'emission' Id = Column(Integer,primary_key=True) Character = Column(String(1), nullable=False) Pinyin = Column(String(7), nullable=False) Potential = Column(Float,nullable=False) classStarting(BaseModel): __tablename__ = 'starting' Id = Column(Integer,primary_key=True) Character = Column(String(1), nullable=False) Potential = Column(Float,nullable=False) Model generation See the train/main.py file for the code. The initstarting, initemission, and init_transition respectively correspond to the initial probability matrix in the generated hidden Markov model, the emission probability matrix, the transition probability matrix, and the generated result is written into the sqlite file. The data set used in the training is the lexicon in the stuttering participle. Because there is no long sentence to train, the result of the last run proves that it can only be applied to the short sentence input. Initial probability matrix The statistical initialization probability matrix is ​​to find all the Chinese characters appearing at the beginning of the word, and count the number of times they appear at the beginning of the word. Finally, according to the above data, the probability that these Chinese characters appear at the beginning of the word is calculated, and the Chinese characters without statistics are considered to appear at the beginning of the word. The probability is 0 and is not written to the database. One thing to note is that in order to prevent the probability calculation, the computer cannot be compared because the smaller the calculation, the natural logarithm operation is performed for all the probabilities. The statistical results are as follows: Transition probability matrix The simplest first-order hidden Markov model is used here. It is considered that in a sentence, the appearance of each Chinese character is only related to a Chinese character in front of it. Although it is simple and rude, it can satisfy most situations. . The process of statistics is to find out the set of Chinese characters that appear after each Chinese character in the dictionary, and to calculate the probability. Because this probability matrix is ​​very large, writing data one by one is too slow, and subsequent optimization can be optimized for batch writing, improving training efficiency. The results are as follows: The above picture shows the ten words with the highest probability of occurrence, which is quite in line with daily habits. Transmit probability matrix The popular point is to count the pinyin corresponding to each Chinese character and the probability of use in daily situations. For example, it has two pronunciations: bao and pu. The difficulty is to find the probability of bao and pu appearing. Here, the pypinyin module is used to convert the phrases in the dictionary into pinyin for probability and statistics, but in some places the pronunciation is not completely correct. Finally, the input method will not match the pinyin. The statistical results are as follows: Viterbi implementation The code builds the input_method/viterbi.py file, where you can find up to ten local optimal solutions. Note that there are ten local optimal solutions instead of ten global optimal solutions, but the best one of these ten solutions is global. The optimal solution, the code is as follows: Def viterbi(pinyin_list): """ Viterbi algorithm implementation input method Aargs: Pinyin_list (list): Pinyin list """ Start_char = Emission.join_starting(pinyin_list[0]) V = {char: prob forchar, prob instart_char} Foriinrange(1,len(pinyin_list)): Pinyin = pinyin_list[i] Prob_map = {} Forphrase,prob inV.iteritems(): Character = phrase[-1] Result = Transition.join_emission(pinyin,character) Ifnotresult: Continue State,new_prob = result Prob_map[phrase + state] = new_prob + prob Ifprob_map: V = prob_map Else: returnV returnV Result display Run the input_method/viterbi.py file and simply show the results: Problem statistics: The statistical dictionary generation transfer matrix is ​​too slow to write to the database, and it takes nearly ten minutes to run once. The data of the emission probability matrix is ​​not accurate, and there are always some Chinese characters that do not match the pinyin. The training set is too small and the input method implemented does not apply to long sentences. Yuoto Thanos Stoving Varnish Version
Flavors:
1.Blue Berry ice
15.strawberry kiwi ice
650mAh Puffs vapes,Yuoto Thanos Vape,Stoving Varnish Version Vape,Yuoto 5000 puffs Vape Shenzhen Kester Technology Co., Ltd , https://www.kesterpuff.com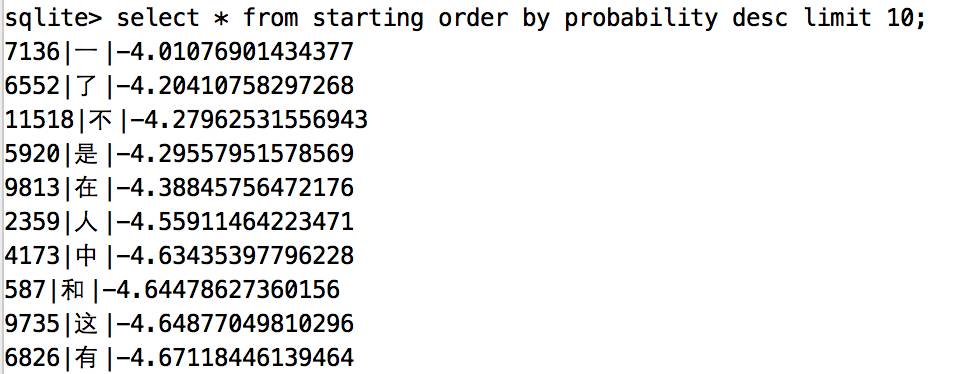



Specifications:
Puffs:5000
Nicotine:5% /2%
E-juice Capacity: 14ML
Battery:650mAh
mesh coil
Rechargeable
2.Energy drink
3.grape ice
4.coke ice
5.mouse chef
6.Mint ice
7.Strawberry ice cream
8.coconut melon
9.strawberry watermelon ice
10.banana ice
11.strawberry peach ice
12.milk coffee
13.antonovka apple
14.watermelon ice